Developers Guide
Motivation
Andes development started in 2018 by David Fishman from the Gulf region to address the aging and deprecated software used by scientific missions. It’s success has led to the adoption of the software as the data-input interface in groups from other regions. These other groups not only also have the similar need to modernized their data input workflow, but recognize that using similar tooling may lead to a lowering the barrier related to inter-regional data sharing and collaboration. Efforts are made (see 2022 Atlantic ReferenceCatch list Workshop) to aid in the data exchange/management between regions. Andes as a data input tool plays a pivotal role in this effort.
However, the adoption of Andes across different groups comes at a cost. The rapid branching of the functional requirements, user-base and deployment settings entails an increase in the software development and software management workload. The lack of a cohesive data management strategy across different groups within a region has already been identified [DECEMBER DATA SCIENCE MANAGEMENT REPORT], including regional interoperability only exacerbates the problem. The root cause of these issues stem mainly from lack of governance for these scopes. There is currently no administrative support for grassroots initiatives such as Andes.
Scientists that choose to use Andes as their main data-input solution need some kind of assurance of long-term support. The initial investments of onboarding users (although minimal) and downstream data consumption workflows (analysis, publication, archiving) need to be offset by some guarantee of long term operability. Sporadically, these different scientific groups may come across funding for a developer and offer resources. These good-faith gestures however, have the risk of potentially being mainly focused around their own niche requirements, which leaves little for the core codebase.
It is in this is context that, Andes as a project, needs to thrive. Andes cannot depend upon stable core developers nor can it depend on centralized governance. The user requirements are not only scattered across regions, but may also suffer from intra-regional heterogeneity. The goal of this document is to provide some kind of scaffolding to that can be help allow Andes to be self-supporting. No framework can replace dedicated core developers, but until this can be realized, this scaffolding will act as a starting place for some kind of crowd-sourced governance. This can somewhat be seen as some kind of quality management strategy.
This situation is not unique, especially in the open-source software space. The theme of software sustainability has attracted interest and is the subject of numerous studies. General themes from these studies can be applied to Andes as a good-will attempt at giving it a a framework that can support its growth and activity.
To contribute to this effort developers are encouraged to:
- follow/contribute to the guidelines of this document
- communicate this situation to their managers, have them allocate resources dedicated to core maintenance
- contribute to core architecture when possible
- review the system architecture when possible
-
create work-groups and periodically communicate with Andes developers from different regions
- keep the code open source
- avoid using deprecated libraries, update them when possible
- avoid situations that can lead to vendor lock-in.
- Happy coding.
Versioning and fixtures
We won’t be following the semantic versioning specification as this won’t be pertinent for the majority of end-users (and there aren’t 3rd party developers for now). As such, we will be using a versioning scheme mainly to assist Andes admins and developers.
A rather common pattern amongst admins is to deploy Andes instances for missions. This involves loading recent fixtures from the a shared andes-preprod instance. The fixtures take the form of an Andes backup which has a filename of the form:
andes_<MAJOR>.<MINOR>_<SHA>_<DATE>.json
The <SHA> represents the git hash of the code responsible for the creation of the backup. This allows to checkout the same branch before reloading the fixtures and ensures that the database contents matches the source code.
The <MINOR> revision denotes dependency changes (like changes to requirements.txt or settings). This means that re-installation of dependencies should follow the checkout of the source code before the fixtures can be loaded.
Lastly, the <MAJOR> version is incremented whenever migrations are squashed —or “crushed”—into a single file per app. This entails that the migrations pertaining to a different “major” version, cannot be applied to the instance and that the database must be dropped and re-initialized whenever the source code changes major versions.
Developers should create a new version (git tag) to indicate minor or major changes as described above.
Code contribution process
As is with the majority of modern software these days, git is used as the system for version control.
The cloud-based service is provided by Github.
Attempts to be service agnostic should be made, although exceptions are allowed—as of this writing, the code is embedded in the Github ecosystem (github-actions, issue-tracking, code reviews, etc).
An effort should be made to migrate these services to other providers (included self-hosted) should Github policies suggest a change of stance.
There are countless ways to use git, the diagram below shows a typical code injection pattern for Andes:
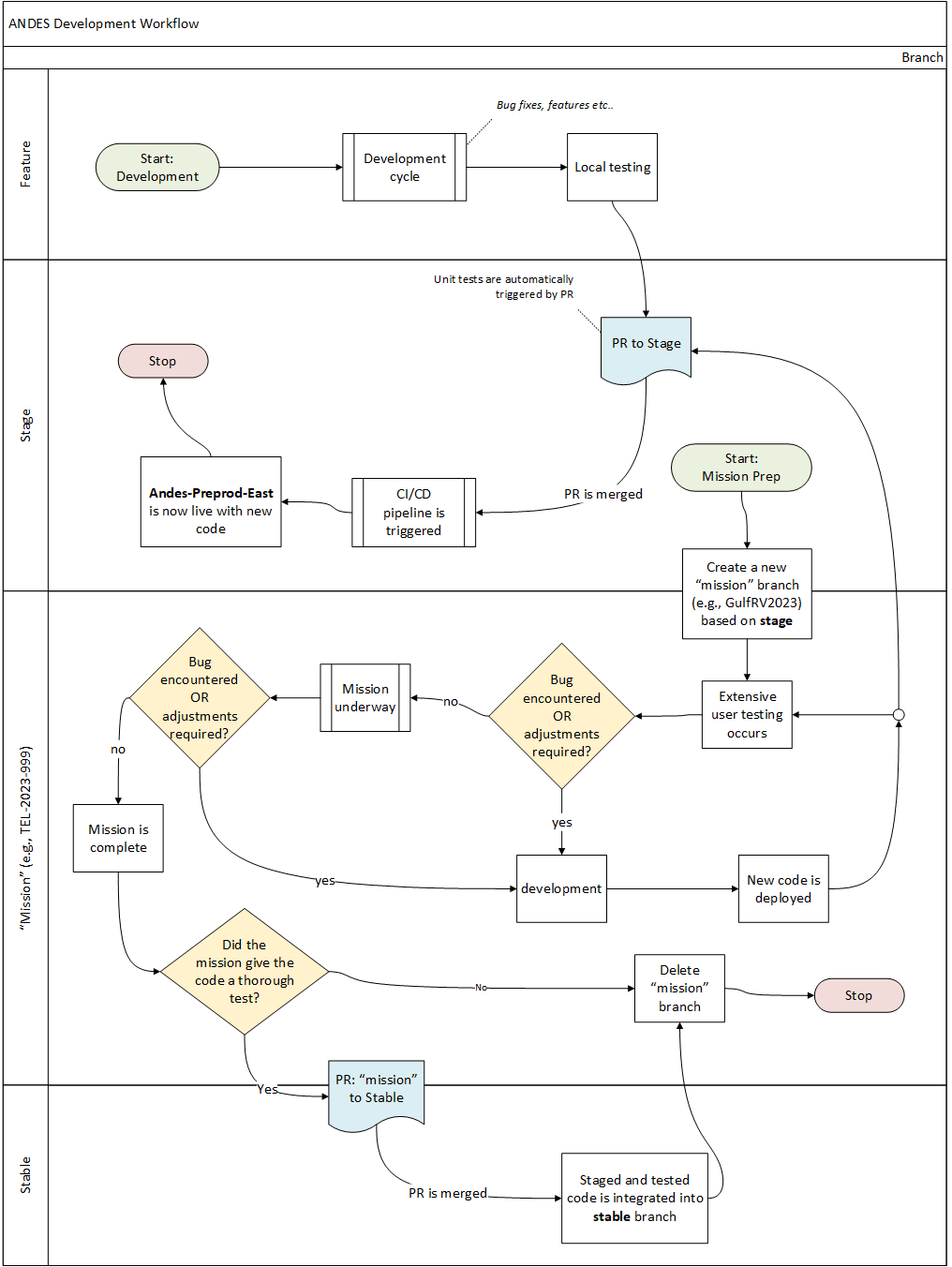
The most active “working” branch having the most recent additions is stage.
New code will live it in own feature branch, initially created from stage.
The feature branches have a short description prepended by feature/.
For example a new feature that allows to plug many gps receivers could be called feature/mulitpleGPS
New features arriving from a from a feature-branch will be merged to stage after a pull-request with code-review.
So you want to merge your code?
Once a feature branch is ready a pull-request an be created. Triggered on pull-requests creation, a series of tests are performed on the code contained in the feature branch. The goal is to have all tests pass prior merging, or even consideration of a review. These serve as the first wave of automated quality-control tests.
Requirements for merging feature branches
A series of tests are performed as github actions (see workflows yaml files under .github/workflows).
The tests are triggered by pull-requests from feature branches to stage.
It is expected that all tests pass prior to merging.
The github actions are meant as a safeguard, it is best do not to rely too much on them to run the tests. Ideally, all the tests should be performed locally by the creator of the feature branch prior to the creation of a pull-request. That being said, Github currently provides generous usage limits. Unless these limits are reached, it should be fine to only run the tests via the actions on their provided runners.
The badges reflecting the status of these requirements are shown at the top of the Readme.md.
These are meant to convey a general sense of the code quality and attract attention to failing tests.
At the moment of writing, there are no hard enforcement of these tests. Merging feature branches can be done at the discretion of the code reviewers.
Passing Unit-tests
Regression testing is performed by using the unittest framework wrapped by Django.
It is expected that develops run the test suite on their feature branch prior to the creation of a pull-request.
Run in the project root:
python manage.py test
or specify the test file for faster results
python manage.py test shared_models.test.test_views
or even a single test case
python manage.py test shared_models.test.test_views.TestMissionCreateView
It is faster to run tests in parallel if you have multiple cores, just add the --parallel flag
python manage.py test --parallel
More info
- workflow file:
.github/workflows/tests.yaml - https://docs.djangoproject.com/en/4.1/topics/testing/
Internationalization (i18n)
English is used a core language in strings that live inside the application layer. However, Django uses the framework provided by the Gnu Translation project to change the value of the english strings to a french translation. These translation have to be created manually and live inside a human readable file.
Andes is meant to have users across regions. As a matter of fact, at the time of this writing the Gulf, Maritimes and Québec regions have used Andes in one shape or form. As these regions covers the full spectrum of official languages (francophone, anglophone and bilingual), internationalization (i18n) has to be a functional requirement to be considered in the development stage. Untranslated text are displayed in english, which is the core language used in the source code.
Developers are encouraged to also provide translations to the strings they add. However, because all translations are found in the same file, and because file paths are displayed differently on different systems, conflicts are highly likely if translations are provided for every new feature.
Consequently, developers are encouraged NOT to provide translations for every new feature, but rather create periodic translations on dedicated branches.
Note that there exists another data layer that does not fall within the reach of the i18n framework.
Andes uses a database that contain tables with text fields.
Where this occurs, an effort is made to both have variants appended with _fr and _en.
For the sake of simplicity and user experience, these are nullable fields and can thus be left blank.
There is no verification of the amount of rows containing blank _fr or _en entries.
Although this falls outside the application layer of Andes (it depends on the database the user connects to), a database snapshot is provided as a starting point and some effort can be made to provided one with fully populated fields.
Django leverages existing gettext frameworks which we discuss below.
For in-depth documentation on Django’s internationalization, see https://docs.djangoproject.com/en/3.2/topics/i18n/translation/
Quickstart
By default, english is used for strings and french translations need to be generated.
In Python code, the gettext() should be used to mark code that will need a translation.
The function _() is typically used as short-hand for the gettext() or gettext_lazy() functions.
It’s frowned upon to use this in the globally, so import it only when needed.
Thus, the _() function can now be used to mark translatable strings.
Comments directly above the _() functions will be scraped and made available to translators.
from django.utils.translation import gettext as _
def my_view(request):
# This comment will appear to translators, send them tips!
output = _("Welcome to my site.")
return HttpResponse(output)
A similar marking will is needed for the Jinja templates.
Use {% load i18n %} near the top of the template and use the translate tag
{% comment %} This comment will appear to translators{% endcomment %}
<title>{% translate "This is the title." %}</title>
Once code is written, a translation file (with the .po extension) has to be created.
django-admin makemessages -l fr
The file django.po should appear under ./locale/fr/LC_MESSAGES.
From there, translators (i.e., developers) can fill in the french for the empty strings.
The makemessages directive will not overwrite existing translations.
One can perform a health check of the translations with the --statistics option of the msgfmt utility,
cd ./locale/fr/LC_MESSAGES
msgfmt --statistics django.po
results in the output:
2017 translated messages, 202 fuzzy translations, 384 untranslated messages.
Inspection of the .po file can be done with the python polib module.
For example, the test threshold of 90% translated entries can be verified.
pip install polib
import polib
po = polib.pofile('locale/fr/LC_MESSAGES/django.po')
frac = po.percent_translated()
print(frac>90)
will print true is more than 90% of the strings are translated.
This .po file can be converted to a binary form (for faster lookups), however it suffices that this only file be staged to github when new strings are created.
Interesting bug: escaping single quotes, apostrophes
It’s possible that the presence of a single quote character used as an apostrophe prematurely end a string. Consider the javascript line:
let msg = '{% trans "This set set is linked to an oceanographic sample. Are you absolutely sure you want to delete it?" %}';
with it’s translation:
"Ce trait est associé a un échantillon océanographique. Voulez-vous vraiment "
"l'éffacer ?"
Will yield the following
let msg = 'Ce trait est associé a un échantillon océanographique. Voulez-vous vraiment l'éffacer ?';
This is obviously bad. This also suggests one can one inject code via a translation?
One can try to use a different apostrophe character or try to escape the single quote character. It turns out it needs to be escaped twice.
"Ce trait est associé a un échantillon océanographique. Voulez-vous vraiment "
"l\\'éffacer ?"
let msg = 'Ce trait est associé a un échantillon océanographique. Voulez-vous vraiment l\'éffacer ?';
Database migrations
With the new ANDES deployment pattern, it is now becoming increasingly difficult (impossible) to squash migrations into a single file.
It is typical to create many migrations (database iterations) during the development of a feature branch. It’s probably a good idea to avoid staging all these files to git until the VERY LAST MINUTE. Once the development cycle is at its end and the code is ready to be merged, the migrations that were create can be merged into a single file (by deleting and re-creating them).
It’s probably cleanest to also avoid merging migrations that were created by other feature branches, this allows to have a linear migration history (i.e., 0023, 0024, 0025, etc).
Procedure
Use these commands at any time to see the state of your development database.
- run
python manage.py showmigrationsto see the state of your dev database - run
git statusto see all unstaged migrations files from your dev branch
- Undo your local migrations by migrating the DB into an old state (ex,
python manage.py migrate shared_models 0060) do this for all apps that need it. This will delete the database data that existed in your new schema. - Delete your migration iterations. Delete all the migration files that relate to your feature branch.
- Pull from stage:
git pull origin stage. This will bring in any changes from stage into your feature branch. - Make new migrations:
python manage.py makemigrations. This create your feature’s migrations as a single file (one file per affected app). - Migrate:
python manage.py migrate. This will update your dev database with all the new changes (yours and the ones pulled from stage). - Test your code, make sure it’s fine.
- Stage your migration file(s) and push it into your feature branch.
- Merge your branch with a PR.
More info
workflow file: .github/workflows/locales.yaml
- https://docs.djangoproject.com/en/3.2/topics/i18n/translation/
- https://www.gnu.org/software/gettext/
- http://translationproject.org/html/welcome.html
Style Guide
The widely adopted PEP8 style guide is always a good place to start. https://peps.python.org/pep-0008/ It’s not too long to read through and explains some of the motivations for the stylistic choices. Some parts of it can be bothersome, like having a maximum line width of 79 characters. Solid arguments as well as consensus within a team should lift any PEP8 requirement.
The easiest way to enforce a style is to use tooling such as an autoformatter. This enforces code conformity at the price of developer freedom. It may feel intrusive at first, but it removes significant weight and makes space for thinking about code logic. The tool has been designed to not affect logical flow. This autoformatter is used by the developers of the Django project.
For a less invasive solution, linters can be installed. These provide code feedback as it is written and developers are free to ignore or follow the recommendations.
Tooling
Developers are encouraged to install these extensions/plugins as it will help take care of styling.
Flake8 linter
[https://flake8.pycqa.org/]
pip install flake8
The linter Flake8 can also be used to enforce styling rules, but it will also catch syntax errors and bugs.
Passing the Flake8 check may be used as a requirement for PRs.
The flake8 configuration is found in pyproject.toml, come rules were added to be used alongside black.
Although the linter can be used at the command-line, it is much more valuable to have it integrated with the code editor for immediate feedback.
The VSCode extension cornflakes is a flake8 wrapper.
Integration with PyCharm is also possible.